Instrukcja
Tworzenie konta
Korzystanie z Korpusomatu należy rozpocząć od rejestracji, czyli założenia konta użytkownika, w ramach którego będzie można zarządzać tworzonymi korpusami. Do założenia konta wystarczy podanie adresu e-mail i hasła użytkownika.
Konto można stworzyć klikając tutaj lub w przycisk w menu w prawym górnym rogu.
Tworzenie korpusu
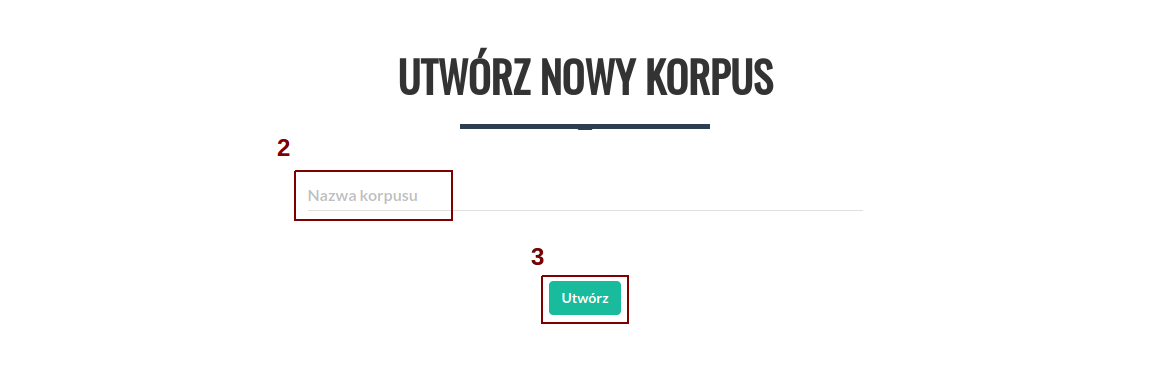
Aby utworzyć nowy korpus (po uprzednim zalogowaniu się) należy kliknąć odnośnik "Nowy korpus" (1) z górnego menu.

Następnie należy wybrać nazwę dla korpusu (2) i kliknąć przycisk "Utwórz" (3).
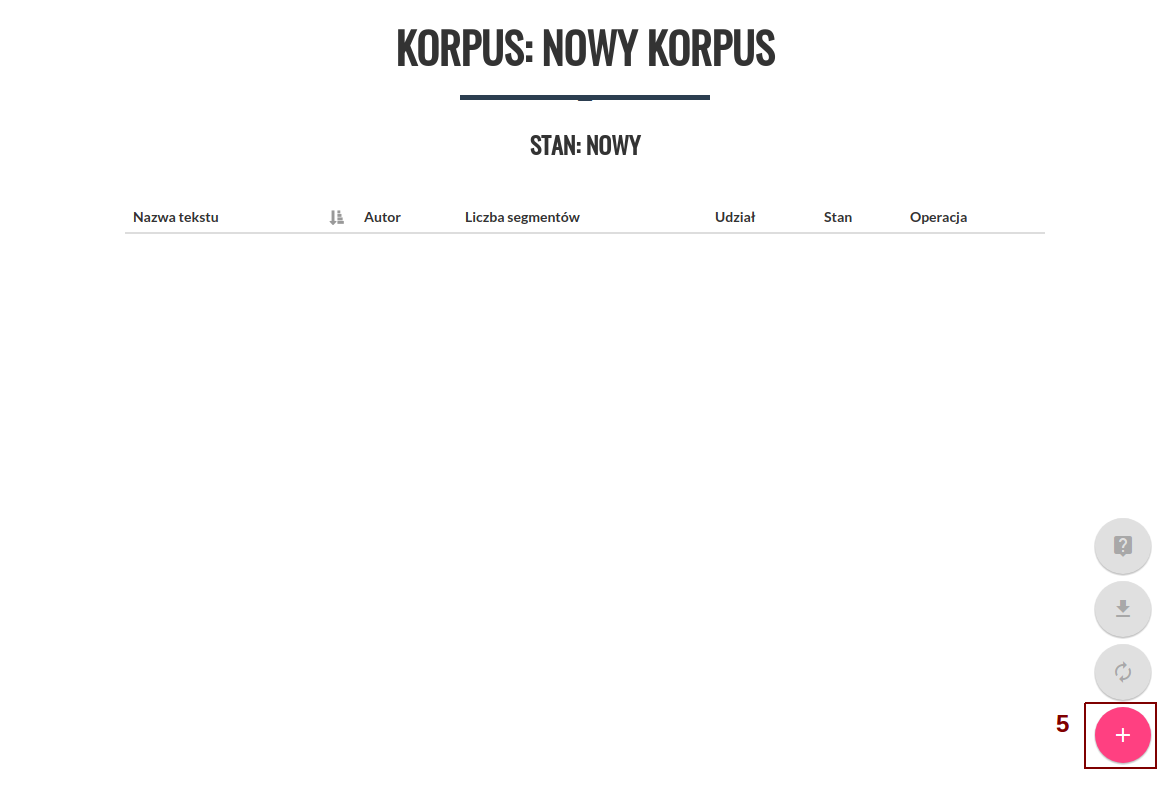
Po utworzeniu korpusu zostaniemy przeniesieni do ekranu "Moje korpusy językowe". Aby rozpocząć dodawanie tekstów do nowo utworzonego korpusu należy kliknąć jego nazwę (4) na liście korpusów. Na tym ekranie wyświetlane są także dodatkowe informacje o korpusach, jest tu również możliwe usunięcie niepotrzebnego korpusu.

Aby dodać nowy tekst do korpus należy następnie kliknąć ikonę "+" (5) w prawym dolnym rogu ekranu.
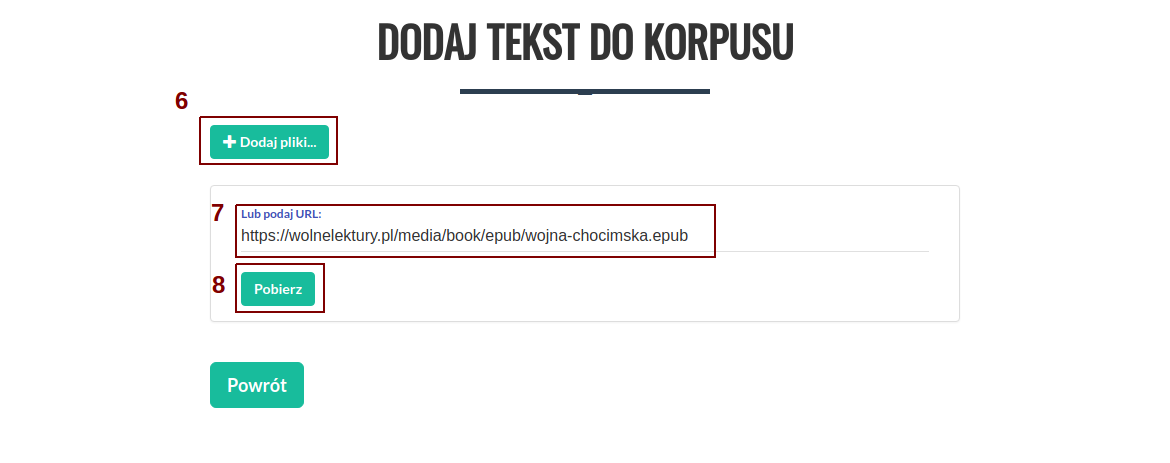
Po kliknięciu zostaniemy przeniesieni do ekranu dodawania tekstu. Lista dozwolonych formatów znajduje się tutaj. Dodać teksty możemy na dwa sposoby.
Pierwszym jest kliknięcie górnego przycisku "+ Dodaj pliki" (6), który pozwala na dodawanie plików z lokalnego dysku. Po kliknięciu pojawi się okno wyboru plików, w którym możemy wskazać jeden lub wiele plików jednocześnie do dodania do korpusu.
Drugim sposobem jest podanie bezpośrednio linku do tekstu w polu tekstowym "Lub podaj URL:" (7), a następnie kliknięcie przycisku "Pobierz" (8). Korpusomat pobierze wtedy plik automatycznie i przetworzy go. W takim przypadku możliwe jest również podanie linku do artykułu (np z portalu internetowego), z którego zostanie wydobyta treść i przetworzona do pliku txt.
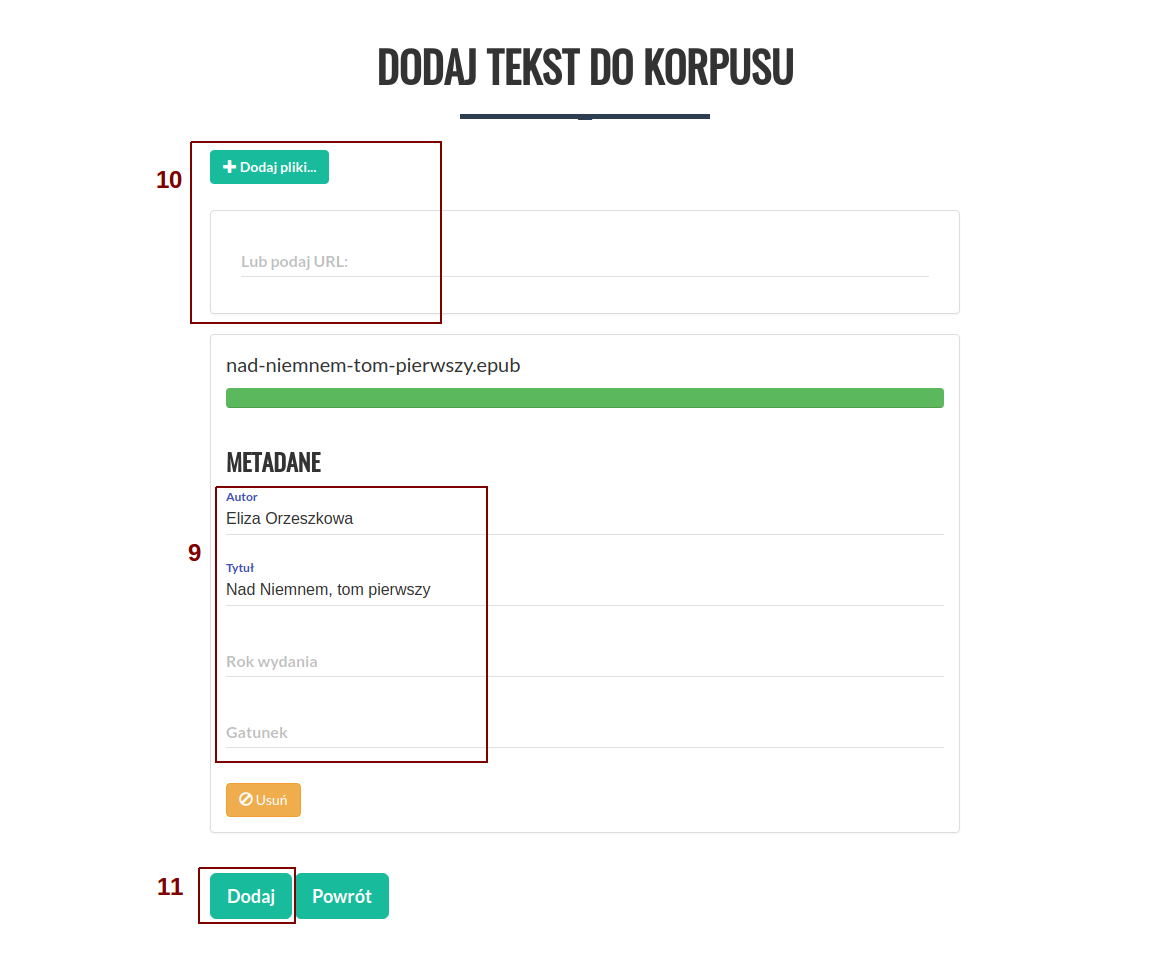
Po przetworzeniu wybranych tekstów istnieje możliwość edycji metadanych (9) lub dodania kolejnych tekstów (10). Korpusomat automatycznie próbuje uzyskać metadane z dodanego pliku, jednak nie zawsze jest to możliwe. Automatyczne rozpoznawanie metadanych "spodziewa się" nazwy pliku w formacie: "autor - tytuł (miejsce, rok)". Przykładowo, aby korpusomat automatycznie rozpoznał metadane Pana Tadeusza z nazwy pliku, dodany plik powinien nazywac się "Adam Mickiewicz - Pan Tadeusz (Paryż, 1834).txt". Powyższe dotyczy plików w formatach, które nie posiadają dedykowanych pól na metadane - nie dotyczy np plików epub, z których metadane zostaną uzyskane z samego pliku, a nie z jego nazwy.
Przed zatwierdzeniem istnieje możliwość ręcznej edycji metadanych.
Do dodawania kolejnych tekstów służą przyciski na górze (10). Metoda dodawania jest identyczna jak w przypadku pierwszego tekstu.
Gdy wszystkie teksty są już dodane, a ich metadane są poprawnie ustawione, należy kliknąć przycisk "Dodaj" (11) na dole ekranu, aby dodać wybrane teksty do korpusu.
Po dodaniu tekstów zostaniemy przeniesieni do ekranu korpusu, a korpusomat zacznie analizę fleksyjną i ujednoznacznianie dodanych plików. Przy nazwie korpusu pojawi się stan korpusu (12). Przy każdym z tekstów będzie wyświetlony status przetwarzania (13). Podczas analizy będzie to "Trwa przetwarzanie". Czas przetwarzania przeciętnej wielkości książki o objętości ok. 80-100 tys. słów powinien wynieść około 2-3 minut, choć częściowo zależy to również od aktualnego obciążenia serwera. Obecnie maksymalny czas przetwarzania pliku wynosi 10 minut – zadania dłuższe zakończą się niepowodzeniem. Gdy wszystkie teksty zostaną przetworzone, a ich stan będzie "Gotowy", można przystąpić do dalszej pracy z korpusem. Na tym ekranie możemy dodać kolejne teksty (14) lub wygenerować korpus binarny (15). Generacja korpusu binarnego jest wymagana aby umożliwić przeszukiwanie korpusu.
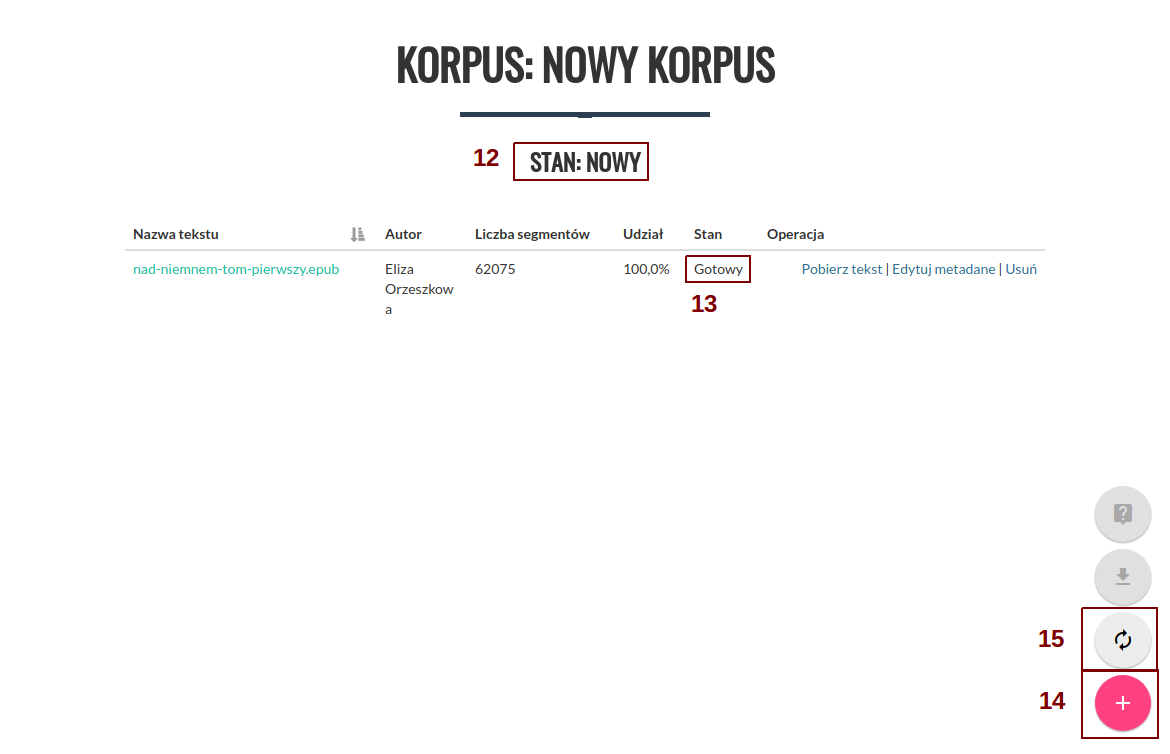
Po wygenerowaniu korpusu binarnego nowy korpus jest gotowy do pracy, a jego status zmieni się na "Utworzony" (16). Przyciski służące do wyszkiwania w trybie online (17) oraz pobrania korpusu binarnego (18) stają się teraz aktywne i możemy rozpocząć korzystanie z korpusu.

Nawet po wygenerowaniu postaci binarnej ciągle można edytować korpus, czyli usuwać lub dodawać do niego teksty. Należy jednak pamiętać, by po takiej operacji ponownie wygenerować binarną postać korpusu, inaczej przy próbie pobrania lub wyszukiwania w trybie online zostanie użyta stara, ostatnio wygenerowana wersja.
Korzystanie z korpusu
Dalsze korzystanie z korpusu jest możliwe na dwa sposoby.
Pierwszym jest wyszukiwanie w trybie online, dostępne po kliknięciu przycisku (17), a drugim skorzystanie z wyszukiwarki Poliqarp na komputerze użytkownika i załadowanie do niej archiwum z korpusem, które pobieramy po kliknięciu przycisku (18). Pierwsza metoda jest nieco ograniczona, ponieważ nie pozwala jeszcze na wykonywanie zapytań statystycznych. Planowane jest jednak dodanie tej możliwości także do wyszukiwarki online.
Wyszukiwanie online
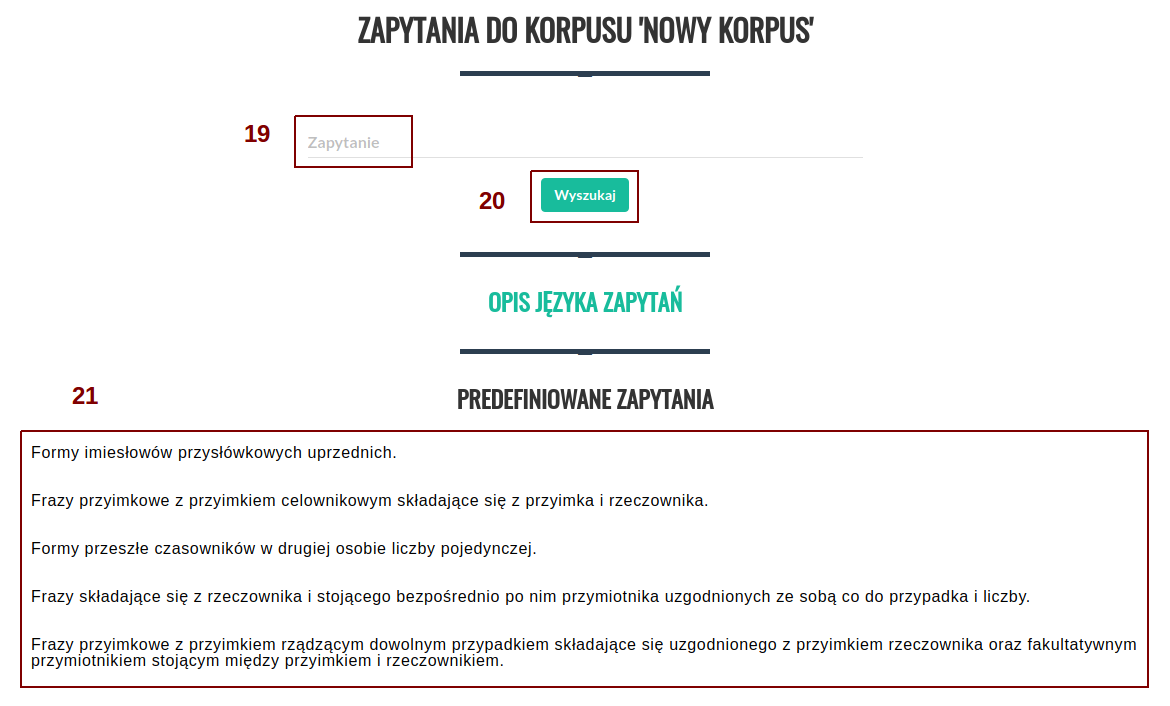
Po kliknięciu przycisku (17) zostaniemy przeniesieni do ekranu wyszukiwania. W polu "Zapytanie" (19) należy wpisać zapytanie, które chcemy wykonać, a następnie wcisnąć przycisk "Wyszukaj" (20). Opis języka zapytań dostępny jest na stronie NKJP. Można również skorzystać z przykładowych predefiniowanych zapytań z listy na dole strony (21).
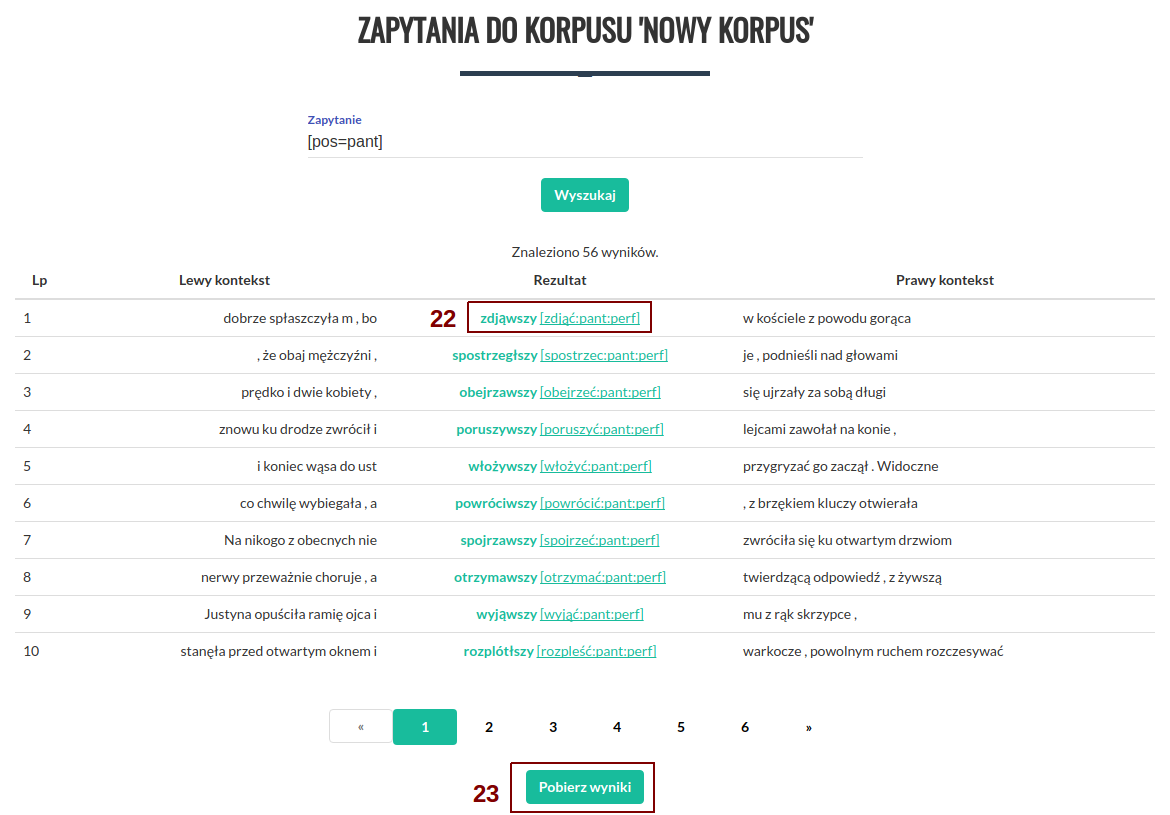
Po wykonaniu zapytania zostaniemy przeniesieni do strony z wynikami, które możemy przeglądać. Dodatkowo możemy wyświetlić dodatkowe informacje o kontekście znalezionego wyniku, klikając na niego (22) lub pobrać całą listę wyników w formie pliku csv (23).
Wyszukiwanie za pomocą klienta Poliqarp
Alternatywną metodą jest skorzystanie z wyszukiwarki Poliqarp instalowanej na komputerze użytkownika. Ta metoda pozwala dodatkowo na wykonywanie zapytań statystycznych.
Pliki instalacyjne wyszukiwarki Poliqarp w wersji 1.3.13 można pobrać ze strony http://clip.ipipan.waw.pl/Poliqarp
Użytkownicy Windows powinni pobrać plik poliqarp-1_3_11.zip i zainstalować program w standardowy sposób. Jeśli na komputerze nie jest zainstalowane środowisko Java, również należy je zainstalować, przechodząc na stronę internetową firmy Oracle proponowaną przez instalator i postępując zgodnie z instrukcjami pojawiającymi się na stronie. Jeśli na komputerze było już wcześniej zainstalowane środowisko Java, to Poliqarp powinien być od razu gotowy do pracy. Program można uruchomić za pomocą pliku run.bat.
Użytkownicy Linuksa mogą pobrać z repozytorium plik poliqarp_1.3.13.tar.gz, rozpakować i uruchomić na komputerze lub zainstalować pakiety deb, jeśli korzystają z dystrybucji Debian lub pochodnej (np. Ubuntu). W tym drugim wypadku należy pobrać i zainstalować pakiet poliqarp-base_1.3.13_i386.deb lub poliqarp-base_1.3.13_amd64.deb w zależności od tego, czy użytkownik korzysta z komputera z procesorem 32- czy 64-bitowym. Oprócz tego należy również zainstalować pakiet poliqarp-gui_1.3.13_all.deb, jeśli użytkownik chce, by wyszukiwarka działała w trybie graficznym (możliwe jest jednak przeszukiwanie korpusu za pomocą Poliqarpa również w trybie konsoli tekstowej). Pakiet z interfejsem graficznym wymaga zainstalowania środowiska Java (Runtime Java Environment), które należy zainstalować zgodnie z wymaganiami swojej dystrybucji Linuksa.
Po uruchomieniu Poliqarpa wystarczy załadować pobrany i rozpakowany uprzednio korpus, wybierając z menu Plik pozycję Otwórz korpus i wskazując katalog, w którym się znajduje. Od momentu załadowania korpusu można go przeszukiwać za pomocą takiego samego języka zapytań, jaki dostępny jest w webowej wyszukiwarce Poliqarp dla NKJP, a zatem można się posiłkować opisem języka zapytań zamieszczonym na stronie NKJP. Oprócz prostych zapytań o wyszukanie konkretnych słów, można również wykorzystywać znakowanie fleksyjne, np. znaleźć wszystkie wystąpienia form rzeczownikowych o rodzaju żeńskim, wpisując zapytanie: [pos=subst & gender=f]. Należy oczywiście pamiętać, że automatyczne znakowanie fleksyjne nie jest bezbłędne. Język zapytań stosowany w NKJP pozwala również odwoływać się do metadanych o tekstach wpisanych przez użytkownika na etapie budowania korpusu
Ponadto, Poliqarp od wersji 1.1. ma również wbudowany moduł statystyczny, który rozszerza nieco język zapytań wyszukiwarki i pozwala na łatwe gromadzenie pewnych danych statystycznych z korpusu. Niestety, moduł ten nie został włączony do webowej wersji Poliqarpa wykorzystywanej w NKJP i m.in. dlatego jest dość słabo udokumentowany. Stosunkowo najlepszy opis możliwości tego modułu można znaleźć na stronie Poliqarpa 1.1 (niestety, tylko po angielsku). Za jego pomocą można np. stworzyć listę frekwencyjną wszystkich rzeczowników w korpusie, wpisując zapytanie:
[pos=subst] group by base sort by freq count all